
Here is something nobody tells you when you ship your first production AI agent: the launch is the easy part.
You've tested it. You've done UAT. You've shown it to stakeholders who nodded and said "impressive." You've wrestled with the prompt until it behaves correctly on every case you thought of. Then you go live, and within a few weeks, you start noticing things.
The agent doesn't call the tool it should. It gives an answer that's technically not wrong but completely misses what the user obviously meant. It handles a new type of question it's never seen before and does so with the confidence of someone who has no idea they're confused. You fix the prompt. It gets better for that case. Then two other cases get worse. You fix those. Something else shifts.
This is agent drift. It's not a bug in the traditional sense. It's the gap between the static thing you built and the dynamic reality it's operating in.
I've been running production AI agents for over three years, across consumer-facing products, internal operations tooling, and planning systems. The drift problem is real, it's persistent, and it doesn't get solved by staring at prompts.
Why the Standard Fixes Don't Scale
When an agent starts behaving badly, most people reach for one of three tools, all of which are legitimate and widely used, but each with a ceiling.
Prompt editing. This is often the right first move. A well-crafted system prompt is the foundation of any well-behaved agent, and prompt engineering is a genuine skill. The limitation shows up at scale: as you add more cases, the prompt grows, instructions start to conflict, and a change that improves one behavior quietly degrades another. The problem isn't that prompt engineering is wrong. It's that it doesn't compound well over time in a dynamic system.
Fine-tuning. For stable, well-scoped domains where you have large volumes of high-quality labeled examples, fine-tuning is powerful. It can meaningfully improve consistency and reduce inference costs. The challenge in agentic contexts specifically is that the task distribution keeps shifting, labeled agentic traces are expensive to produce, and the feedback loop between a regression and its discovery can be weeks long. It's a strong tool for the right problem. Post-deployment drift in a multi-agent system is a harder fit.
Guardrails and output validation. Essential, not optional. You should have these regardless of what else you're doing. The gap is that guardrails are inherently reactive. They protect against failure modes you've already identified. They don't help you when the agent makes a mistake you haven't anticipated yet.
All three of these belong in a mature agentic system. The question isn't whether to use them. The real question is what to reach for when they've been applied and the drift problem persists. That's the gap this pattern is trying to fill.
The Research That Exists (And the Gap It Leaves)
There's real work in this space worth knowing about.
Reflexion (Shinn et al., 2023) has agents store verbal self-critiques in episodic memory and retrieve them on future similar tasks, which is the closest thing to what I'm describing. Self-RAG (Asai et al., 2023) teaches a model to retrieve and critique its own outputs inline. Self-Refine (Madaan et al., 2023) builds iterative improvement loops through feedback. DSPy from Stanford systematizes prompt optimization in ways that mechanize some of what I'll describe here.
These are all valuable. None of them give you what actually matters in a deployed production system: a human-facing admin panel where real interactions get reviewed, annotated by either a human or a judge agent, and fed back into a retrieval system that dynamically improves the agent's behavior on the next similar request, all without touching the model weights.
That end-to-end pattern is what I've started calling Retrieval-Augmented Self-Improvement (RASI). I couldn't find a paper that names and formalizes exactly this. If you know of one, tell me. If you don't, maybe it's worth writing.
The Architecture
The core loop looks like this:
A user sends a request. The agent does its work: thinking, tool calls, state changes, final response. The interaction is logged in full, including the question, the reasoning trace, every tool called, and the final output. A feedback signal is collected. Sometimes this is explicit (a thumbs up or down, a comment). Sometimes it's implicit. Did the user follow up immediately with a rephrasing? Did they abandon the conversation? Did they escalate to a human?
Interactions that look problematic get flagged. A human reviewer, or a judge agent operating with its own evaluation rubric, examines the flagged interactions. The judge asks: did the agent call the right tools? Was the reasoning sound? Did the answer match what the user actually needed, not just what they literally typed?
The result of that evaluation is a structured example, not just a question-answer pair, but a full trace with explicit annotation:
- What the agent did
- What the agent should have done
- Why the gap exists
- What the correct behavior looks like, in enough detail that a model can learn from it
That example gets embedded and stored in a vector database. When the next request arrives that's semantically similar to something in the store, the relevant examples are retrieved and injected dynamically into the agent's context before it starts reasoning.
The agent doesn't just see the task. It sees: here is a case like yours, here is how it was handled badly, here is what good looks like. It has, in effect, learned from the failure, without any retraining.
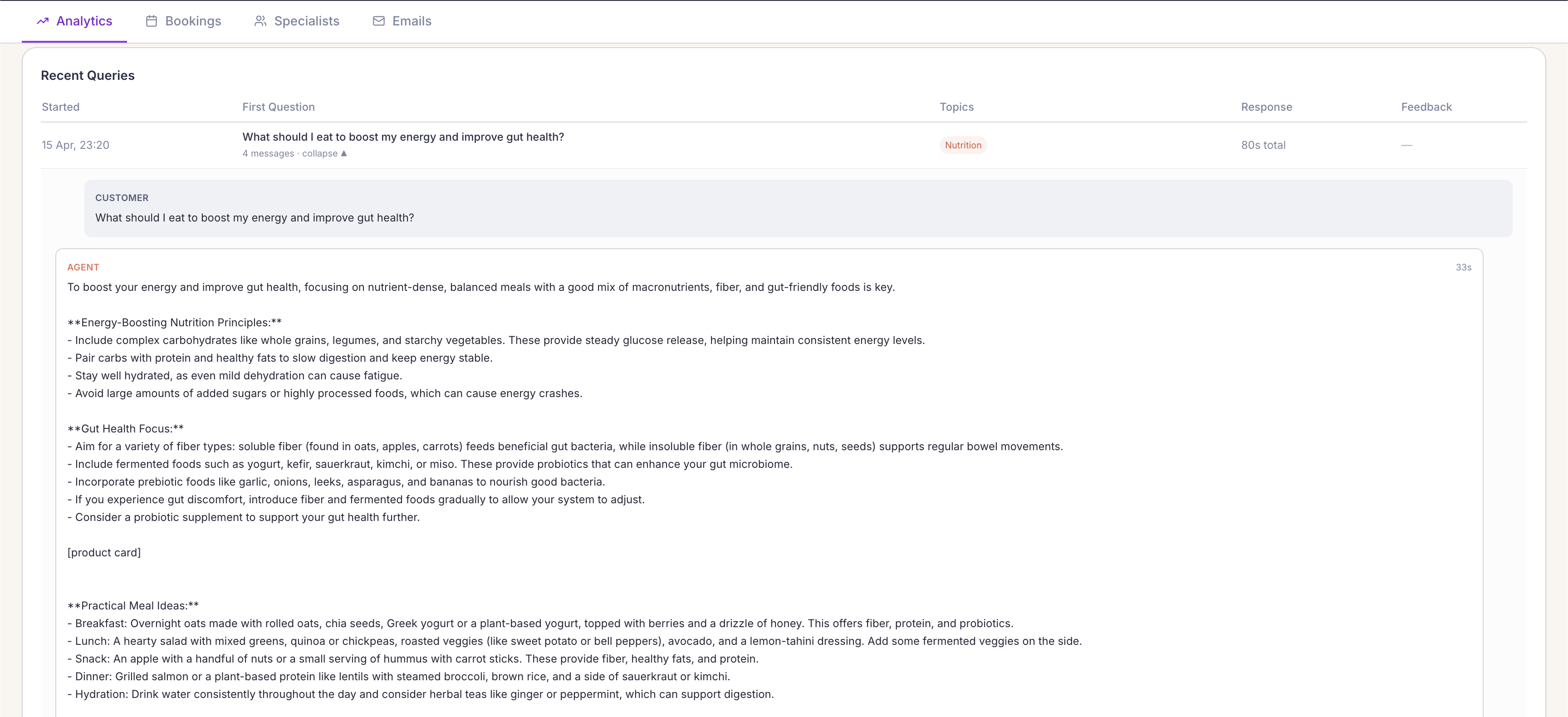
This is what the admin monitoring panel looks like in practice. Every interaction logged, the full agent reasoning visible, topics classified automatically, and a feedback column ready to be populated, either by a user signal or a reviewer.
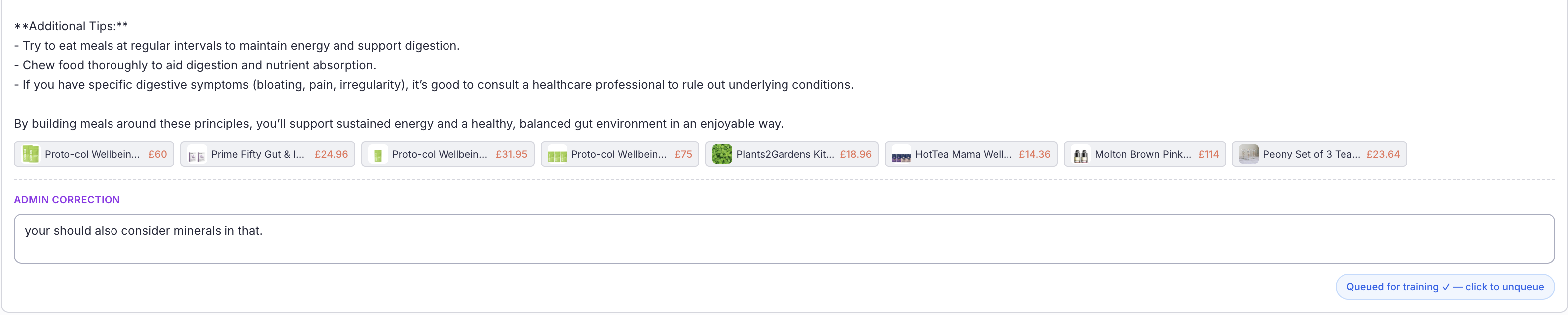
The admin correction box at the bottom is where the feedback loop starts. In this case, a nutrition assistant gave a solid answer about gut health and energy, but a reviewer noticed it didn't consider minerals. That correction, combined with the original question and the agent's full response, becomes a labeled example. Next time someone asks a nutritionally similar question, the agent has context it didn't have before.
Why This Might Be Better Than Fine-Tuning
This is the part I want to be direct about, because it's not obvious until you think through the mechanics.
It's instantaneous. Add an example to the vector store and it's available on the next request. No retraining cycle. No deployment. No waiting.
It's reversible. Delete a bad example and it's gone. A bad fine-tune is not easily undone. You're peeling changes out of weights you can't directly inspect.
Negative examples are first-class citizens. Showing a model "don't do this, do this instead" is something fine-tuning handles poorly. The model tends to learn the pattern, not the contrast. In a RASI setup, the negative trace sits right next to the positive one with an explicit lesson attached. The model reads it. The distinction is clear.
It's interpretable. You can read every example in your store. You know exactly what's being injected into the context and why. When something goes wrong, you can trace it. Fine-tuning is a black box by design.
It tracks domain drift. As your user base evolves and the distribution of requests shifts, your example store shifts with it. It happens automatically because you're continuously adding examples from the current distribution. You don't need to detect drift and trigger a retraining job. The system adapts in the background.
The closest academic framing is in-context learning with curated episodic memory. But that phrase doesn't capture the operational loop: the admin panel, the judge agent, the continuous annotation pipeline. That's the part that makes it work in production, not in a research paper.
A Note on Privacy, Legal, and Responsible AI
I want to be honest about the part that's complicated, because skipping it would be irresponsible.
Storing agent interactions means storing what users said. Depending on your context, that data may be personally identifiable, commercially sensitive, legally regulated, or all three. Before building a RASI system on a customer-facing product, you need answers to questions like: what are you allowed to store? For how long? Who can access it? What needs to be anonymized before it enters your example store? What does your privacy policy say about this?
These aren't technical questions. They're legal and governance questions, and the answers vary by jurisdiction, industry, and the nature of the user relationship.
That said, and this is worth paying attention to, many organizations already have an environment where these constraints are minimal or nonexistent. That environment is internal agents.
If you're running AI agents on internal workflows (procurement, planning, operations, HR tooling, knowledge management), your users are employees, your data governance is internal, and your legal surface area is dramatically smaller. Internal agent interactions are often fair game for full logging, annotation, and reuse as few-shot examples, provided your internal AI usage policies allow it.
This makes RASI almost trivially deployable for internal agentic systems, and significantly more valuable. Internal workflows tend to have well-defined correct behavior, clear domain expertise among the reviewers, and a high tolerance for iteration. It's the ideal environment to build and validate the loop before you decide how much of it to apply to your external-facing products.
Start there. Get the pattern working. Then figure out what version of it applies externally, given your specific constraints.
The Caveats You Should Know
I'm describing a pattern I believe in. I'm also going to tell you where it breaks down.
Example conflict resolution. As your store grows, you will accumulate examples that point in different directions. One says "always retrieve before answering." Another says "for short factual questions, answer directly." When both get retrieved for the same request, the agent needs to reconcile them. You need either a recency or confidence weighting, a pre-injection synthesis step, or hard limits on how many examples per category can land in a single context.
Context window pressure. Every example you inject is tokens. At scale, you need discipline about how many examples you retrieve and how concise each one is. A verbose example store injecting 2,000 tokens of context on every request is going to create problems, both in cost and in model performance as the context fills up.
Example quality amplification. This is the real one. A bad example in a fine-tuning dataset gets averaged out by everything around it. A bad example in your RASI store gets retrieved and injected whenever something semantically similar appears. Bad examples don't get diluted here. They get targeted. Your curation process matters more than it does in traditional training.
The Loop, in Plain Terms
The agent drifts. You see it. You annotate it, or your judge agent does. The annotation becomes an example. The example enters the store. The next similar request retrieves the example. The agent behaves correctly because it's seen the failure and knows what to do instead. You didn't change the model. You didn't rewrite the prompt. You added one piece of structured knowledge to a retrieval system, and the system used it at exactly the right moment.
That's not learning in the machine learning sense. There's no gradient. No weight update. No training loop.
But it might be better. Because it's immediate, traceable, reversible, and it compounds. Every interaction you annotate makes the system marginally more capable for the next similar request. Over time, the example store becomes institutional knowledge, not about the domain, but about how the agent should reason about the domain.
That's a property I'd take over a fine-tuned model any day.
This pattern came out of a conversation about what it actually takes to maintain production AI agents over time, not just deploy them. If you're working on something similar or have seen this formalized elsewhere, I'd genuinely like to know. Find me on LinkedIn.